Hadoop is an open-source framework that allows distributed processing of large data sets across clusters of commodity machines using a simple programming model.
Hadoop was first developed as a Big Data Processing system in 2006 at Yahoo!
This idea is based on Google's MapReduce,which was first published by Google based on their proprietary MapReduce implementation.
In the past few years, Hadoop has become a widely used framework for storing & processing Big Data.
Big Data Picture With Hadoop

HDFS (Hadoop Distributed File System) - Storage
Stores different types of large data sets (i.e. structured, unstructured and semi structured data)
HDFS creates a level of abstraction over the resources, from where we can see the whole HDFS as a single unit.
Stores data across various nodes and maintains the log file about the stored data (metadata)
HDFS has two core components, i.e. NameNode and DataNode.
Hadoop-based Big Data System :

Hadoop : Master/Slave Architecture
Scenario : A project Manager managing a team of four employees. He assigns project to each of them and tracks the progress.

YARN (Yet Another Resource Negotiator)
Performs all your processing activities by allocating resource and scheduling tasks
Two services : ResourceManager and NodeManager
ResourceManager : Manages resources and schedule applications running on top of YARN
NodeManager : Manages containers and monitors resource utilization in each container
ResourceManager & NodeManager
ResourceManager : Master daemon that manages all other daemons & accepts job submission.
Allocates first container for the AppMaster.
NodeManager : Responsible for containers, monitoring their resource usage i.e. (CPU, memory, disk, network) & reports the same to RM.
AppMaster :
- One per application
- Coordinates and manages MR jobs
- Negotiates resources from RM
Container : Allocates cluster resources (memory, CPU etc.) to a slave node (NM).
MapReduce : Data Processing Using Programming
Core component in a Hadoop Ecosystem for processing.
Helps in writing applications that processes large data sets using distributed and parallel algorithms.
In a MapReduce program, Map() and Reduce() are two functions
Map function performs actions like filtering , grouping and sorting
Reduce function aggregates and summarizes the result produced by map function.
Anatomy of a MapReduce Program

PIG : Data Processing Service using Query
PIG has two parts: Pig Latin, the language and the pig runtime, for the execution environment.
1 line of Pig latin = approx. 100 lines of Map-Reduce job
The compiler internally converts pig latin to MapReduce.
It gives you a platform for building data flow for ETl (Extract, Transform and Load)
PIG first loads the data, then performs various functions like grouping, filtering, joining, sorting, etc. and finally dumps the data on the screen or stores in HDFS.
HIVE : Data Processing Service using Query
A data warehousing component which analyses data sets in a distributed environment using SQL-like interface.
The query language of Hive Query Language (HQL)
2 basic components : Hive Command Line and JDBC/ODBC driver
Supports user defined functions (UDF) to accomplish specific needs.
What is Apache Hive ?
- Data Warehousing Software Utility.
- Used for Data Analysis
- Built for SQL users
- Manages Querying of Structured data
- Simplifies and abstracts load on Hadoop
- No need to learn Java and Hadoop API
Apache Hive Features :

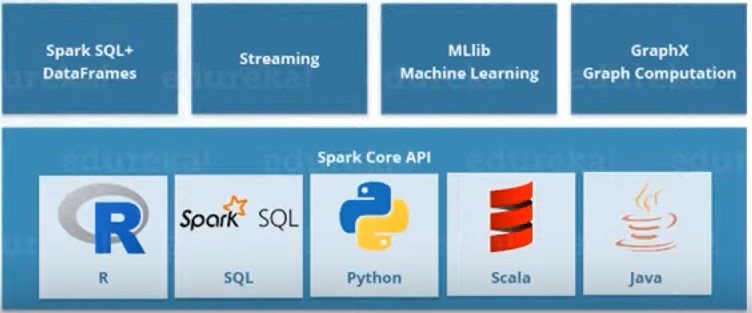
Spark : In - memory Data Processing
A framework for real time data analytics in a distributed computing environment.
Written in Scala and was originally developed at the University of California , Berkeley.
It executes in-memory computations increases speed of data processing over Map-Reduce.
100x faster than Hadoop for large scale data processing by exploiting in-memory computations.
Spark comes packed with high-level libraries
Provides various services like MLlib, graphX, SQL + Data Frames, Streaming services.
Support various language like R, SQl, PYTHON, SCALA , JAVA .
Seamlessly integrates in complex workflow.
Hbase : NoSQL Database
An open source, non-relational distributed database a NoSQL database.
Supports all types of data and that is why, it's capable of handling anything and everything.
It is modelled after Google's BigTable
It gives us a fault tolerant way of storing sparse data
It is written in Java, and HBase application can be written in REST , Avro and Thrift APIs.
HDFS v/s HBase

Oozie : Job Scheduler
Oozie is a job scheduler in Hadoop ecosystem
Two kinds of Oozie jobs : Oozie workflow and Oozie Coordinator.
Oozie workflow : Sequential set of actions to be executed.
Oozie Coordinator : Oozie jobs which are triggered when the data is made available to it or even triggered based on time.
Apache Flume : Data Ingesting Service
Ingests unstructured and semi-structured data into HDFS.
It helps us in collecting, aggregating and moving large amount of data sets.
It helps us to ingest online streaming data from various sources like network traffic, social media email messages, log files etc, in HDFS.
Apache Sqoop : Data Ingesting Service
Another data ingesting service
Sqoop can import as well as wxport structured data from RDBMS
Flume only ingests unstructured data or semi-structured data into HDFS.
ZooKeeper : Coordinator
An open-source server which enables highly reliable distributed coordination.
Apache Zookeeper coordinates with various Hadoop services in a distributed environment
Performs synchronization, configuration maintenance, grouping and naming.
Apache Ambari : Cluster Manager :
Software for provisioning , managing and monitoring Apache Hadoop clusters.
Gives us step by step process for installing Hadoop services.
Handles configuration of Hadoop services.
Provides a central management services for starting , stopping and re-configuring Hadoop services.
Monitors health and status of the Hadoop cluster.



























No comments:
Post a Comment